
Most of risks come from uncertainty of identity.
For example, the well-known phishing, bogus transaction, account theft, and fraud through registration and login are the direct consequences of the uncertainty of identity.
So, how do you make sure your identity is established and that you can't be easily stolen or copied?
Device fingerprinting provides a solution. Device fingerprinting refers to the unique identification of the device generated by the hardware, network, and environmental information of the user's Internet device, and the most important indicators of device fingerprint are uniqueness and stability.
This article starts with the stability and uniqueness of device fingerprinting.
As a unique ID for identifying mobile phone or browser, it's required to collect data from user devices, but it is not easy for device fingerprinting.
First of all, the legal level of the user's personal information data protection authority increased.
In recent years, the protection provisions of personal information data have been continuously tightening the rights of data collection, and the collection rate of features with the unique identification function of the device is becoming less and less, which increases the difficulty of device fingerprint technology to a certain extent.
In the past, the methods for collecting the unique identification of device fingerprint include MAC address (Ethernet physical address), IMEI (mobile equipment identification number), and IDFA (advertising identifier). With the updage of system and emergence of new cheating methods and tools, parameters on the device can be tampered with, turning it into a new device easily, which compromises the effect of unique identification of the device. Therefore, the device fingerprinting requires more information to ensure the uniqueness and stability of the device fingerprint.
Taking iOS as example, IDFA collection on iOS 14 or later requires user authorization, the same applies for Serial and IMEI. This change has made the generation of stable and unique identity more complicated.
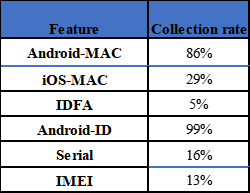
The collection rate of some feature statistics (total number of devices > 500,000), the actual availability rate of android-mac here will be lower, because of arbitrary nature of mac
Second, the amount of abnormal data increases.
Different mobile phone models and operating system versions will lead to different characteristics of the collected data. It's especially so for Android, as there are so many different brands of mobile phones run on Android, with different OS version and ROM, the data collected are inconsistent.
Consider IMEI, the following are actual abnormal data collected.
000000000000000
88888888888888
666666666666667
111111111111119
A000005EAAACCC
868686868686863
444646464643346
100000000150705
010000000053015
A0000060A60A0B
A0000070000AAB
00:00:00:00:00:0a
02:00:00:00:00:00
00:00:00:00:00:01
00:00:00:00:00:10
6a:aa:6a:aa:6a:6a
00:02:00:00:00:00
00:00:00:80:00:00
10:00:00:00:00:12
f2:0f:f0:02:f0:22
32:12:31:23:32:32
66:00:44:40:06:66
c0:00:00:00:00:d0
00:00:00:00:00:12
04:00:00:50:54:04
These abnormal data may be because the device has been tampered with, or abnormal ROM, or special model device, it's also true for android_id, Seria, etc. If these abnormal data are ignored, the effect of fingerprints will definitely be affected. Therefore, it is necessary to have the support of big data to formulate a reasonable fingerprint algorithm.
In addition, the fingerprint calculation algorithm is not static. The release of a new version of operating system and a new model of mobile phone may lead to abnormal data collection at any time, which requires the device fingerprint to have the ability to continuously monitor abnormal data.
Last is the impact of illegal and semi-illegal behaviors.
In the field of risk control, device fingerprint is a basic tool to fight against illegal and semi-illegal behaviors, so there are inevitably ways to bypass the tracking and detection of fingerprints. A common way is to modify the device fingerprint by changing the device fingerprint manually.In addition, the tampering of device information may also cause fingerprint data corruption. If the tampered data is associated with normal user's device, the data of normal user will be compromised, and it is difficult to remove such data from the system.

So this requires changes made to device fingerprinting, Ding Xiang chooses to do so through the cloud + terminal model, in addition to collection of more detailed information, the timeliness and security of equipment have been significantly enhanced, based on the previous experience and data precipitation of the industries. When new attack methods appear, how can fingerprinting technology respond and identify it faster.
How to ensure the stability and uniqueness of device fingerprints?
Let's consider the stability first.
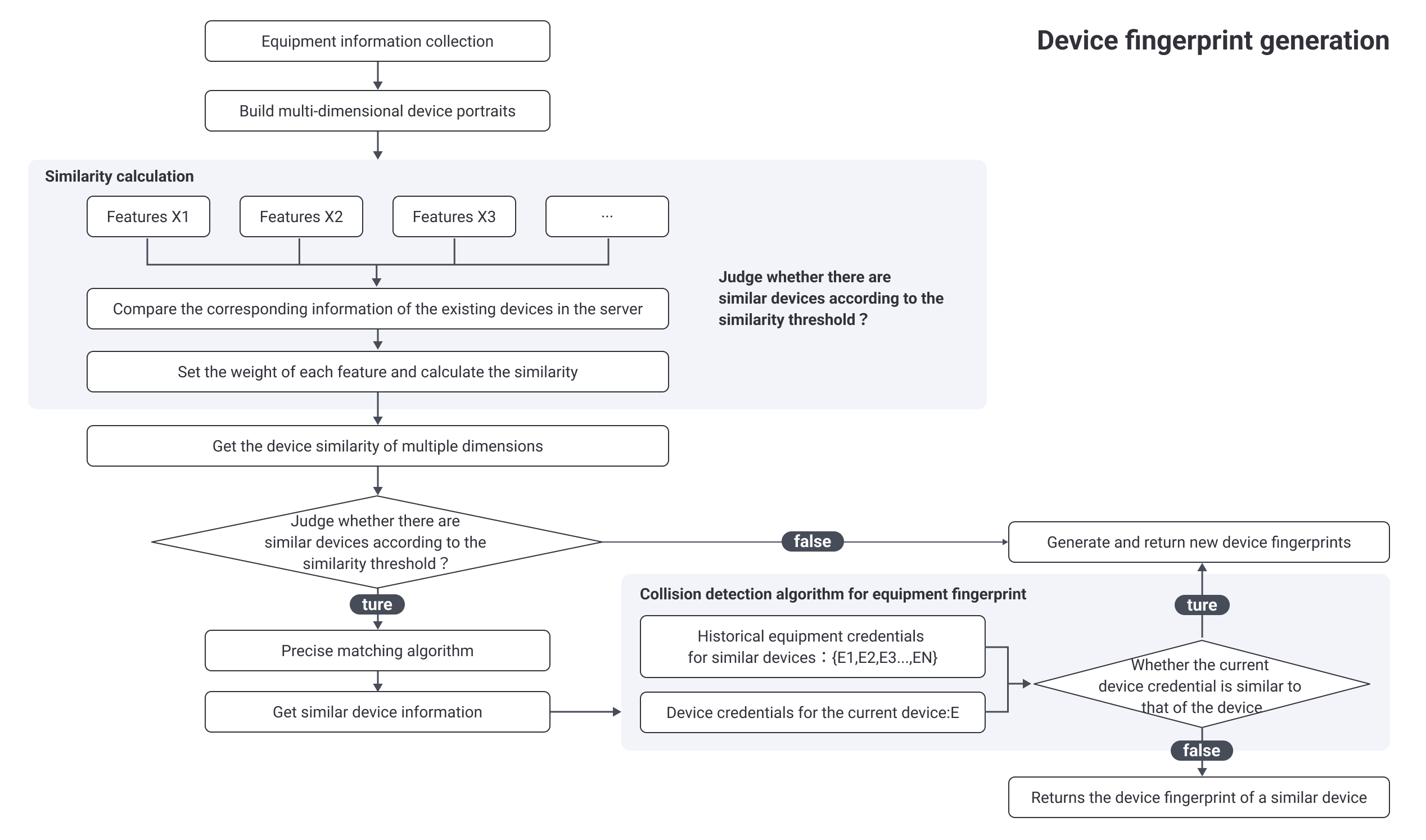
The stability calculation logic is to construct a multi-dimensional device portrait based on the collected data. After reporting the data, the algorithm matches the closest device and uses the found device fingerprint, otherwise, new device fingerprint is generated.
The reason for emphasizing the stability of the device fingerprint is that many operations will cause the characteristic information of the device to change, such as app reinstallation, permission change, advertising identifier reset, machine restart, system upgrade, device parameter modification, and factory reset.
In order to calculate a stable unique identity of the device in these cases, it is of course impossible to rely on only one or two device parameters, and more comprehensive device information is needed to build a device profile.
To ensure the high stability of device fingerprints, it is necessary to collect multi-dimensional data, analyze the degree of discrimination, stability, and change cycle, and analyze the characteristics of the characteristics, and use the characteristics reasonably.
Taking CPU, storage, and memory as example, it has very good stability, but the discrimination is very poor. So such features are not suitable for use alone, it needs to be used together with other features.
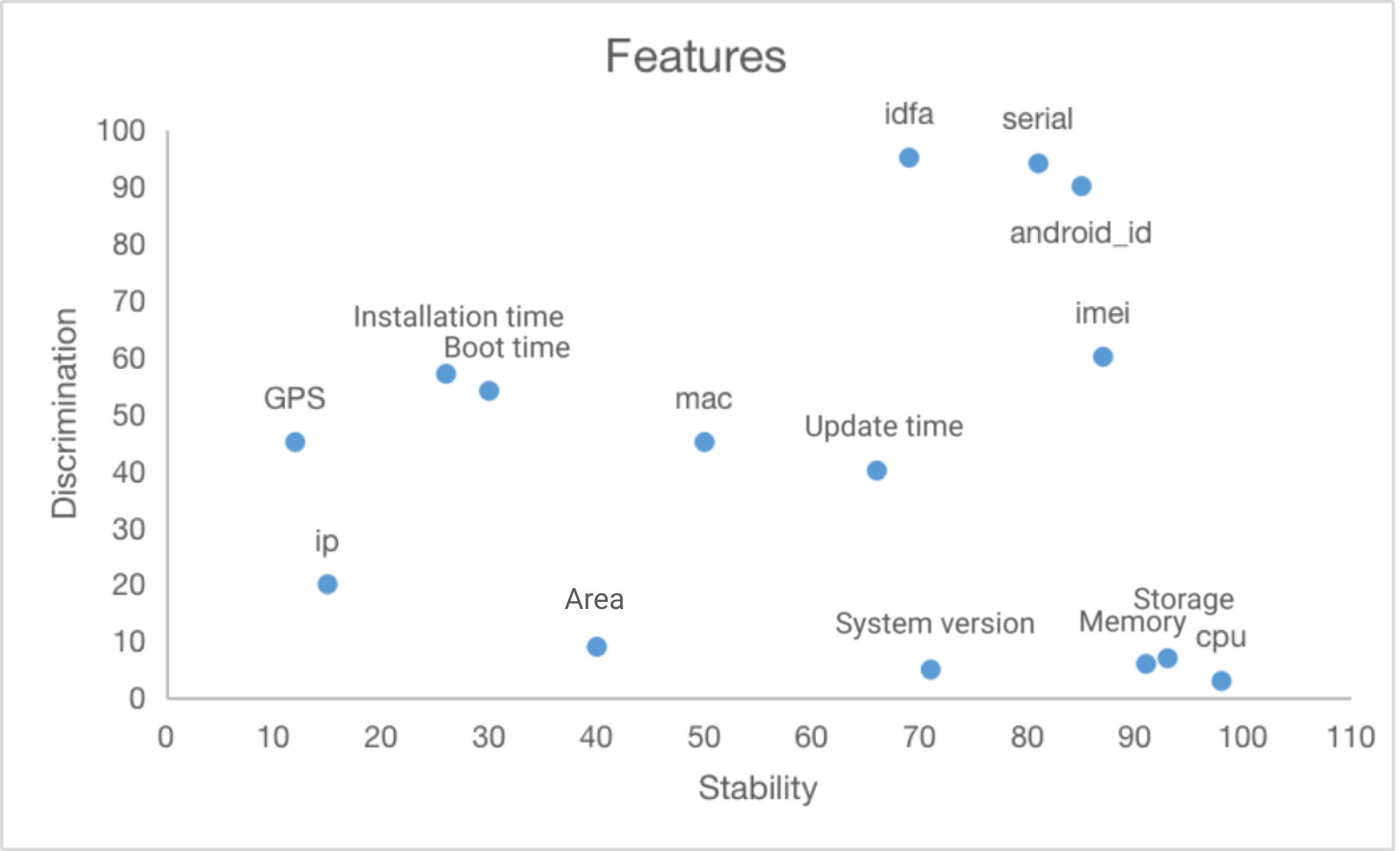
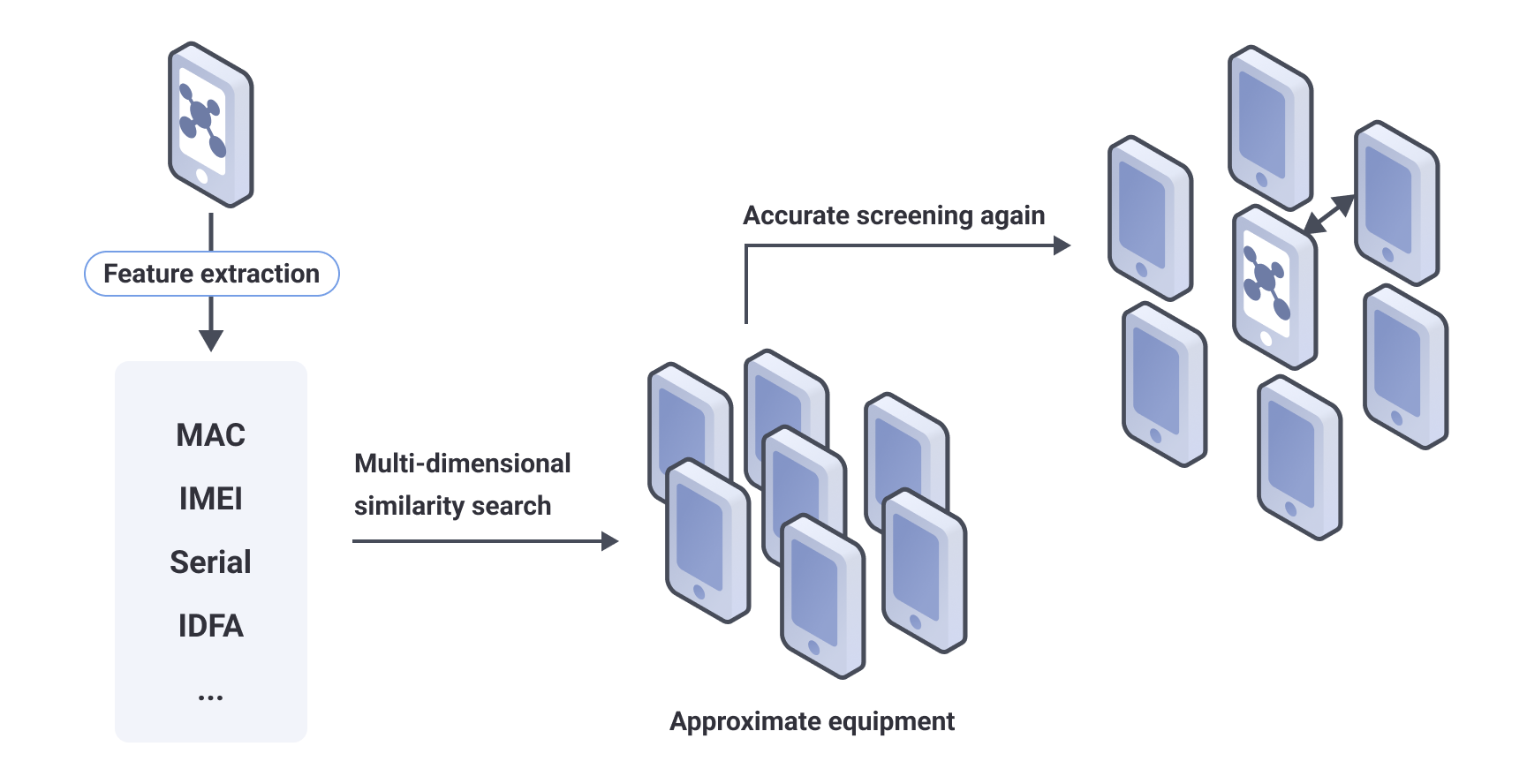
It is necessary for us to further observe the period of feature stability (the size of the period in which the feature remains constant) and the difficulty of the stable change of the feature (the degree of difficulty of changing the feature), and decide how to use the feature based on the different characteristics of the feature, when selecting a feature, it should have an obvious advantage in at least some index. In order to ensure the stability of the device fingerprint, it is necessary to construct multiple device portraits (short-term and long-term) for the device based on different characteristics. First, a batch of similar devices have to be located through the similarity search algorithm, and then accurately picked by the exact matching algorithm.
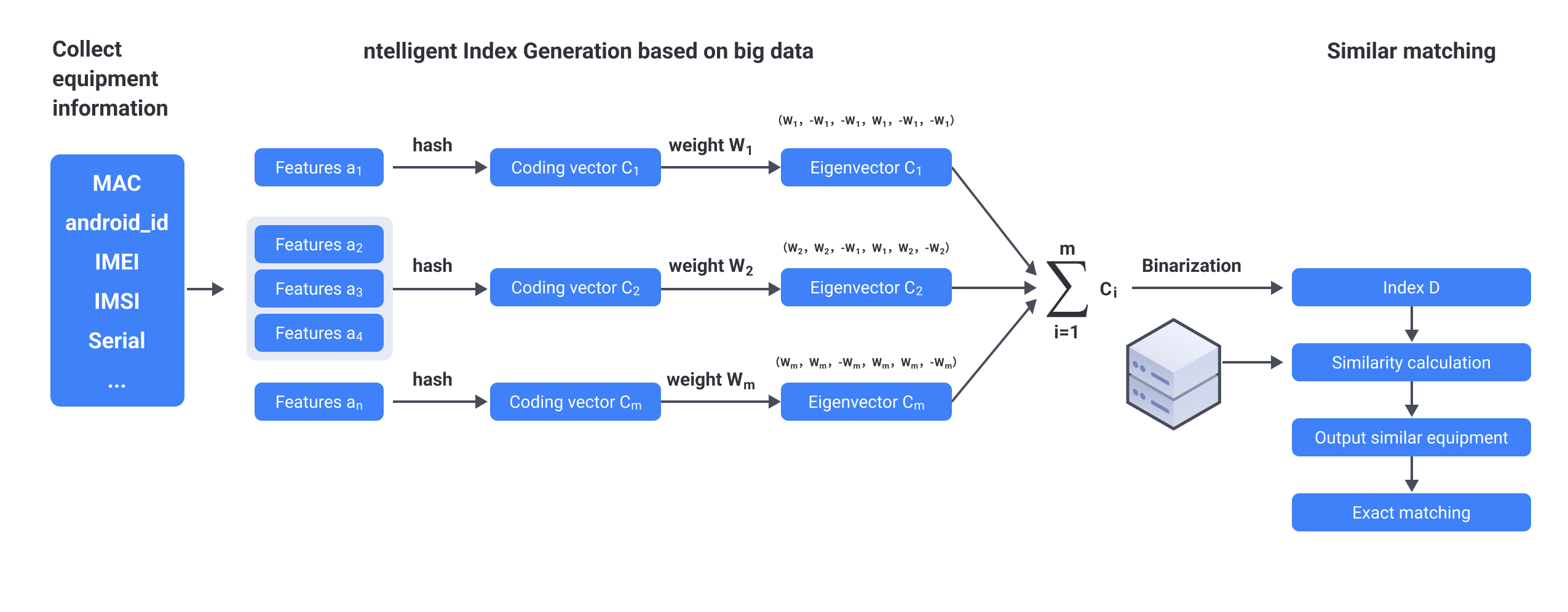
The process of basic algorithm (SimHash) is as follow:
-
Select the device information collected as feature pool;
-
Hash coding the features according to the degree of discrimination, stability, and difficulty of change of the collected information after corresponding processing. For example, splice multiple features with weak discrimination, and hash code to obtain coding vector C;
-
Set the weight W of the coding vector C according to features, (note: weight W can be obtained through big data learning, or set according to expert experience, weight W varies depending on the operating system version of device);
-
Multiply the coding vector C by the corresponding weight W to obtain the feature vector C';
-
Add all eigenvectors C' to get a eigenvector, and binarize (values greater than 0 become 1, and values less than 0 become 0) to obtain the final index D;
-
Calculate the similarity between the index D and the indexes of other devices in the server, (calculate the Hamming distance - in the information coding, the number of different bits encoded on the corresponding bits of the two legal codes is called code distance, also known as Hamming distance. The bit number with different values for the corresponding bits of the two code words is called Hamming distance of two code words. For example, the first, fourth, and fifth digit of 10101 and 00110 are different, so the Hamming distance is 3) return the device information whose similarity is within the threshold as candidate pool for further precise matching.
It should be noted that the stability of device fingerprint depends on whether sufficient and appropriate features are selected, whether the characteristics of each feature are properly understood, and whether the matching algorithm used conforms to the current situation of data acquisition.

Next, let's talk about uniqueness.
Uniqueness is a key indicator of device fingerprinting.
As basic service, device fingerprint is at the core of data services, such as user's commonly used devices, device-dependent policies in risk control, and unique advertising identifier. If there is a deviation in the fingerprint uniqueness calculation, or collision, it may cause serious misjudgment.
For example, after collision, the device may be considered to be in wrong area and associated with wrong account, resulting in erroneous punishment; if there is a large-scale collision, a large number of normal users will be blocked. Collision will affect the reliability of fingerprints, as a result, online services no longer rely on fingerprint-based judgments. Therefore, for good device fingerprint, the uniqueness must not have severe deviation.
The collision may be resulted from non-uniqueness of important equipment features that should be unique, or improper feature selection, lack of unique identifier for a combination of features, or bad matching algorithm.
Therefore, to ensure the uniqueness of the device fingerprint, it requires not only real-time dynamic update algorithm, but also collision detection.

First of all, as far as the algorithm update is concerned, it is not enough to rely on the application of the daily abnormal data detection, it is necessary to analyze the current data regularly in the offline warehouse, and the abnormal features can be found and extracted in time, and then fed back to the online algorithm optimization.
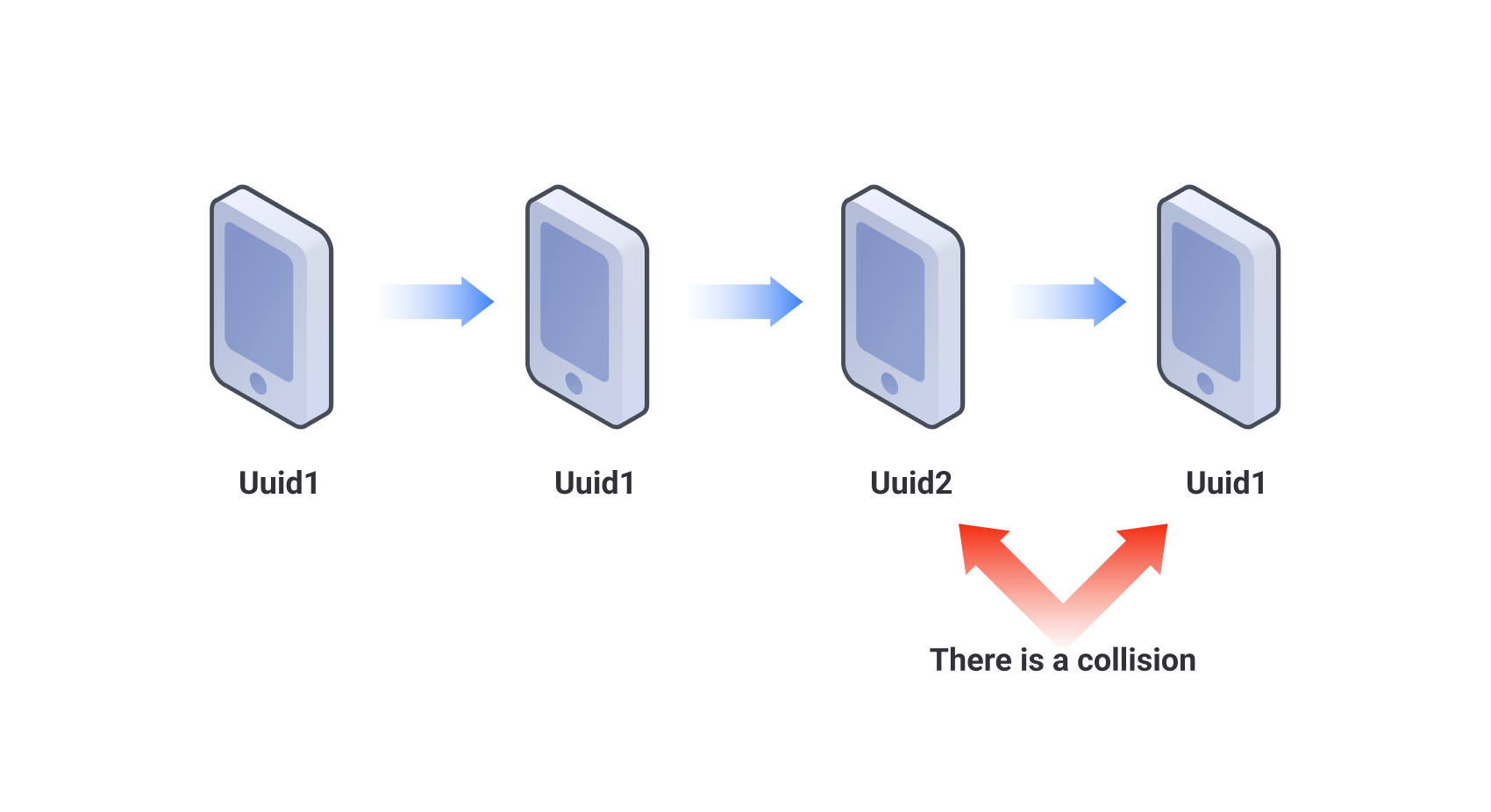
The collision detection of AISecurius device fingerprinting prevents abnormal data from affecting fingerprint data. As device's uuid is irreversible, it can be used to detect collision. For the same device, the data is collected for calculation, the uuid may change during this period, and it cannot be changed back to the previous uuid. If a device has a historical uuid after calculation, it indicates that the calculation is unreliable because device collision occurs.
Basic principles:
-
When the device uses the App for the first time, after reporting the device data collected, the fingerprint server issues a credential and saves in cache. The credential issued for the first time is called credential X1;
-
When the device uses the App again to collect and report device data, it first checks whether there is credential X1 in cache; if yes, carry the credentials X1; if no, it is considered that credential X1 is deleted when clearing the cache, and the fingerprint server issues credential X2, which is different to credential X1;
-
After the credential X2 is generated, if the credential X1 appears again when the device data is collected and reported, it indicates the device fingerprint has a collision;
-
After clearing the cache multiple times, it will include credential X3, credential X4... credential XN. If any of credential X1 to credential X(N-1) appears after credential XN, it means the device fingerprint has a collision;
Of course,There are other ways to detect device collisions, but it is not suitable to follow the calculation idea of the fingerprint, because the application has already 'made a mistake' during the collision, so it is more suitable to use the 'bypass' method mentioned above.
In addition, the calculation process of AISecurius device fingerprint covers data analysis, feature selection, algorithm matching, and collision detection.
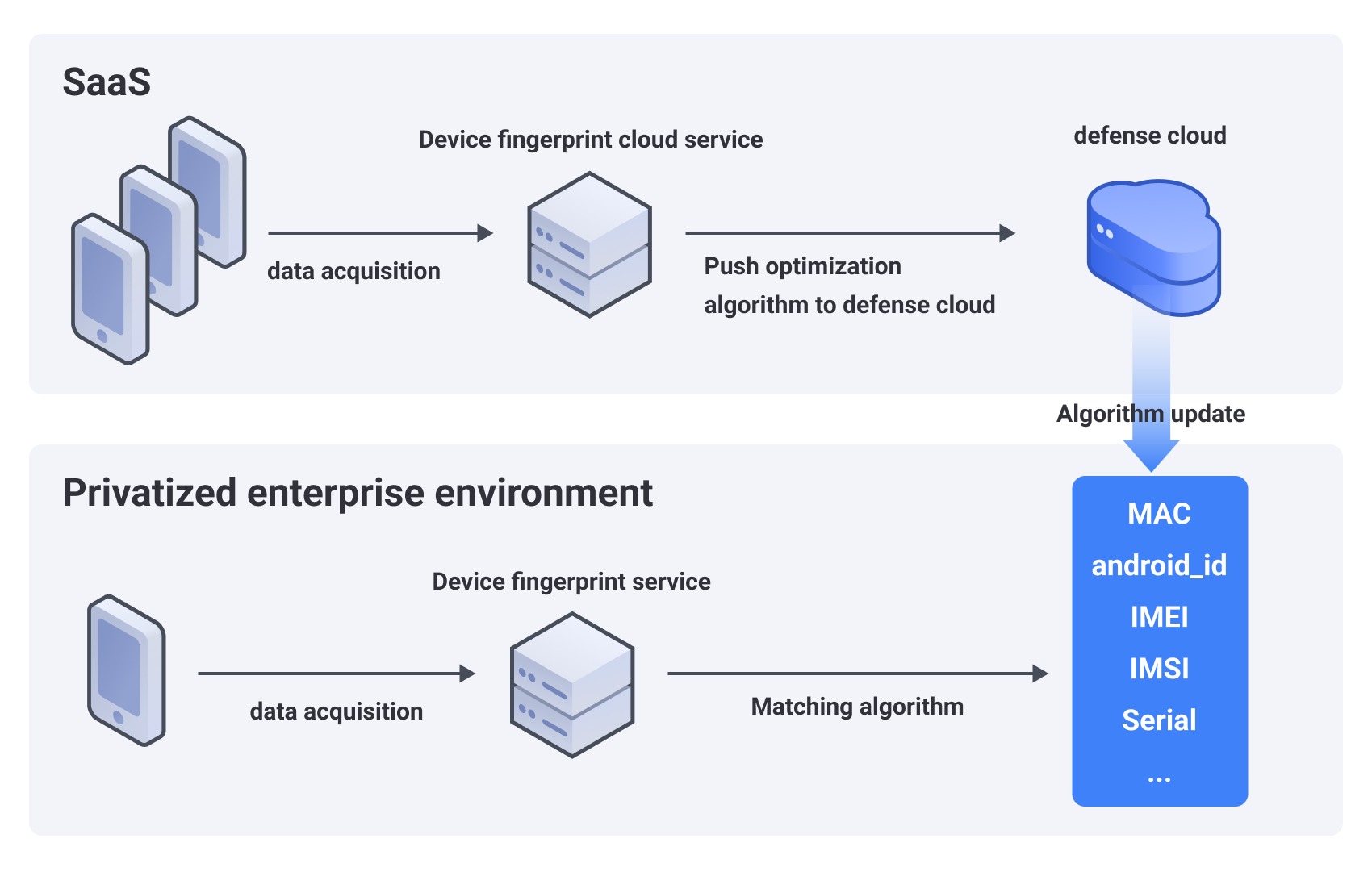
At the same time, for privatized users, AISecurius provides defensive cloud services to synchronize the latest computing algorithms collected by cloud service device fingerprints to the defensive cloud platform, and private fingerprints can be kept up-to-date with cloud services.
In general, in terms of uniqueness and stability, device fingerprinting not only prevent the collection logic from being cracked or data forgery, which ensure authenticity and accuracy from the source of data collection, it prevents the device parameters from being tampered with (including IMEI, MAC address, AndroidId, SIM card information, model, and brand) by disabling or clearing cache and cookies. It guarantees that the device fingerprint remains unchanged and the stability remains above 99%. The device fingerprint ID generated for each device is unique and it's impossible to be tampered with. The uniqueness is maintained at 100%, the response time is less than 0.1 seconds, and the crash rate is less than 1/10000.


